
Father of AlphaGo: About Go, Man Made a Mistake 3000 Years
(Original title: Father of AlphaGo: About Go, Man Made a Mistake in 3000 Years)
#endText .video-info a{text-decoration:none;color: #000;} #endText .video-info a:hover{color:#d34747;} #endText .video-list li{overflow:hidden;float: Left; list-style:none; width: 132px;height: 118px; position: relative;margin:8px 3px 0px 0px;} #entText .video-list a,#endText .video-list a:visited{text-decoration: None;color:#fff;} #endText .video-list .overlay{text-align: left; padding: 0px 6px; background-color: #313131; font-size: 12px; width: 120px; position: absolute; bottom : 0px; left: 0px; height: 26px; line-height: 26px; overflow: hidden;color: #fff; } #endText .video-list .on{border-bottom: 8px solid #c4282b;} #endText .video -list .play{width: 20px; height: 20px; background:url(http://img1.cache.netease.com/video/img14/zhuzhan/play.png);position: absolute;right: 12px; top: 62px;opacity: 0.7; color:#fff;filter:alpha(opacity=70); _background: none; _filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src="http://img1.cache.netease.com/video /img14/zhuzhan/play.png"); } #endT Ext .video-list a:hover .play{opacity: 1;filter:alpha(opacity=100);_filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src="http://img1.cache.netease.com/video /img14/zhuzhan/play.png");}
(See the full version of the video at the end of the article)
澎湃 News Contributing Author Liu Xiuyun
On April 10th, the news of the “human-computer war†was re-emerged. The confrontation between humans and AI once again touched the nerves of the world.
"I will win the mentality and will die. I must beat Alpha Dog!" For May 23 to 27 with the Go artificial intelligence program AlphaGo (Alpha Dog), currently ranked No. Clean release rhetoric. However, the father of AlphaGo (Alpha Dog) said, "We invented Alpha Dog, not to win the Go game."
Demis Hassabis, the father of AlphaGo, recently gave a speech entitled “Exceeding the Limits of Human Cognition†at his alma mater, Cambridge University, to answer the world’s many questions regarding artificial intelligence and Alpha dogs. Doubt - In the past 3,000 years have humans underestimated the importance of the game? Alpha dog won last year, South Korea's nine professional Li Shishi rely on a few tricks? Did the Master, a mysterious chess player who won several international masters at the beginning of this year, be an Alpha dog? Why is Go the puzzle of artificial intelligence?

Jamis Hasabis, founder of Deep Mind, father of 燗lphaGo.
Jamis Hasabis, founder of Deep Mind, father of AlphaGo, began playing chess at the age of 4. The success of the chessboard at the age of eight prompted him to start thinking about two issues that have caused him problems so far: First, how does the human brain learn to accomplish complex tasks? Second, can computers do this? At the age of 17, Hasabis was responsible for the development of the classic simulation game "Theme Park" and was released in 1994. He then completed a computer science degree at Cambridge University and entered the University College London in 2005 to pursue a Ph.D. in neuroscience, hoping to understand how the true brain actually works to promote artificial intelligence. In 2014 he founded the company Deep Mind. The company’s Alfa Dog made a name for himself in the 2016 World War I Go Championship.
In his speech that day, Hasabis revealed the deadly reason that South Korean player Li Shishi lost to Alpha Dog last year. He also mentioned the Chinese chess player Ke Jie who is about to fight Alpha Dog. He said, “Ke Jie is also online and Alpha Dogs have played against each other, after the game Ke Jie said that mankind has studied Go for thousands of years, but artificial intelligence tells us that we didn't even reveal its skin.Similarly, Ke Jie mentioned the truth of Go. Here is the truth of science."

World Go champion Ke Jie is about to face Alpha Dog.
The News site listened to the 45-minute speech of the father of AlphaGo (Faculty of Alpha) at Cambridge University. The dry goods were full. Please do not miss any details:
Thank you very much for being able to be here today. Today, I will talk about artificial intelligence and what DeepMind is doing in the near future. I call this report “Beyond the limits of human cognition†and I hope that by the end of the report, everyone will Clearly understand the ideas I want to convey.
1. Do you really know what artificial intelligence is?
For a friend who does not know DeepMind, I will give you a brief introduction. We established this company in London in 2010. In 2014, we were acquired by Google, hoping to accelerate the pace of our artificial intelligence technology. What is our mission? Our primary mission is to solve the problem of artificial intelligence; once this problem is solved, theoretically any problem can be solved. This is our two major missions. It may sound a bit embarrassing, but we really believe that if the basic problems of artificial intelligence are solved, there is no problem that is difficult.
So how are we going to achieve this goal? DeepMind is now working hard to create the world's first general-purpose learning machine. In general, learning can be divided into two categories: one is to learn directly from input and experience, there is no established program or rules to follow, the system needs to perform its own from the raw data Learning; the second learning system is the universal learning system, which refers to an algorithm that can be used for different tasks and areas, and even new areas that have never been seen before. Everyone will certainly ask, how does the system do this?
In fact, the human brain is a very obvious example. This is possible. The key lies in how to find the most suitable solution and algorithm through a large amount of data resources. We call this system generic artificial intelligence to distinguish it from the narrow artificial intelligence that most of us currently use only in certain fields. This kind of narrow artificial intelligence has been very popular in the past 40-50 years.
The deep blue system invented by IBM (Deep Blue) is a good example of narrow artificial intelligence. He defeated chess champion Gary Kasporov in the late 1990s.å ‘ å·³ å·³ å·³ å·³ 㶠㶠㶠㶠㶠㶠㶠㶠㶠î‡é…‰å†‰îˆ´ XII/p>

In May 1997, IBM and the World Chess Champion Gary Kasparov competed.
2. How to make the machine obey human orders?
Everyone may want to ask how the machine obeys human orders. It is not the machine or the algorithm itself, but the wisdom of a group of clever programmers. They talked with each chess master, learned their experience, translated it into codes and rules, and formed the strongest team of chess masters. But such systems are limited to chess and cannot be used for other games. For new games, you need to start programming again. To a certain extent, these technologies are still not perfect. They are not completely artificial intelligence in the traditional sense. What is missing is universality and learning. We want to solve this problem through "enhanced learning." Here I explain enhanced learning, I believe many people understand this algorithm.
First of all, imagine that there is a main body. In the AI ​​field we call our artificial intelligence system as the main body. It needs to understand its own environment and try its best to find out what it wants to achieve. The environment here can refer to a real event. It can be a robot or a virtual world, such as a game environment. The subject is in contact with the surrounding environment in two ways. It first observes the familiar environment. We first pass the vision, and we can also hear and touch. And so on, we are also developing a multi-sensory system;
The second task is to model and find the best choice on this basis. This may involve expectations of the future, imagination, and hypothesis testing. This subject is often in a real environment. When the time node arrives, the system needs to output the best solution currently found. This program may change the environment more or less, so as to further drive the observations and feedback to the subject.
In simple terms, this is the principle of enhanced learning. Although the schematic diagram is simple, it involves extremely complicated algorithms and principles. If we can solve most of the problems, we can build universal artificial intelligence. This is because of two main reasons: First, from a mathematical point of view, my partner, a Ph.D., he built a system called 'AI-XI'. With this model, he proved the conditions and time in the computer hardware. In unlimited circumstances, build a universal artificial intelligence, the information needed. In addition, from a biological point of view, animals and humans, etc., the human brain is controlled by dopamine, it is in the implementation of enhanced learning behavior. Therefore, whether from the perspective of mathematics or biology, enhancing learning is an effective tool for solving artificial intelligence problems.
3. Why is Go the puzzle of artificial intelligence?
Next, I want to mainly talk about our latest technology, that is, the alpha dog that was born last year. I hope everyone here will understand this game and try to play it. This is a great game. Go uses a square grid checkerboard and black and white two-colored round chess to play chess. There are 19 straight lines on the board to divide the checkerboard into 361 intersections. The chess moves on the intersection, and the two sides alternately play chess. Victory. The Go rules are not complicated and I can teach you in five minutes. This picture shows that the game is over. The entire board is filled with pieces. Then count the space that your piece is surrounded by and the space that the opponent piece. The space is large, and anyone wins. In the illustrated close game, the difference between the white grids is a victory.

White won with a difference of one grid.
In fact, it is very difficult to understand the ultimate goal of this game because it is not as straightforward and clear as chess. In Go, it is totally intuitive. Even how to determine the end of the game is very difficult for beginners. . Go is a long-established game with a history of more than 3,000 years. It originated in China. In Asia, Go has a profound cultural significance. Confucius also pointed out that Go is one of the four major skills that every true scholar should master (piano chess and painting). Therefore, Go is an art in Asia, and experts will play.
Nowadays, this game is even more popular. There are 40 million people playing Go and more than 2,000 top experts. If you show the talent of Go at the age of 4-5, these children will be selected and entered a special specialty. Go school, where students from the age of 6 spend 12 hours a day learning Go, seven days a week, every day. Until you become an expert in this field, you can leave school to graduate. These experts are basically investing all their energy in life and trying to figure out how to master this skill. I think Go may be the most elegant game.
As I said, this game has only two very simple rules, and its complexity is unimaginable. There are a total of 10170 (10 of the 170th power) possibilities. This number is more than the number of atoms in the entire universe. (10 of the 80th power) are all gone, and there is no way to exhaust all possible outcomes of Go. We need a smarter approach. You may ask why computer games for Go are so difficult. In 1997, IBM's artificial intelligence, Deep Blue, defeated then chess world champion Garry Kasparov. Go has always been a mystery in the field of artificial intelligence. Can we make an algorithm to compete with the world Go champion? To do this, there are two big challenges:
First, the search space is huge (branch factor is 200). A good example is that in Go, there are two hundred possible positions for each chess piece, and chess is only 20. The branch factor of Go is much larger than that of chess.
Second, more difficult than this is that there is hardly a suitable evaluation function to define who is the winner and how much is won; this evaluation function is crucial to the system. For chess, writing an evaluation function is very simple, because chess is not only a relatively simple game, but also a physical one. It is easy to draw conclusions by using only two or more pieces. You can also use other indicators to evaluate chess, such as chess mobility.
All of these are impossible in Go. Not all parts are the same, and even a small part of the changes will completely change the pattern, so each small piece has a crucial influence on the game. The hardest part is that I call chess a devastating game. At the beginning of the game, all the pieces are on the board. As the game progresses, the pieces are eaten by each other, the number of pieces decreases, and the game becomes More and more simple. Go, on the other hand, is a constructive game. At the beginning, the board is empty. Slowly playing both sides fills the board.
So if you are going to judge the current situation in the midfield, in chess, you just need to look at the current board and you can tell the general situation; in go, you have to assess what may happen in the future in order to assess the current situation, So compared to Go, it is much harder. There are also many people trying to apply DeepBlue's technology to Go, but the results are not ideal. These technologies cannot even win a professional Go player, let alone a world champion.
So we must ask, even the computer is so difficult to operate, how does humanity solve this problem? In fact, humans rely on intuition, and Go is a game of intuition rather than calculation. So, if you ask a chess player, why would you go this way? He will tell you what kind of purpose you can achieve after you finish the next step and the next step. Such a plan may not always be satisfactory, but at least there is a reason for the player.
However, Go is different. If you ask a world-class master, why do you take this step? They often answer your intuition and tell him to go. This is true, and they cannot explain the reason. We hope to solve this problem by enhancing the artificial neural network algorithm by means of enhanced learning. We try to imitate this intuitive behavior of humans through deep neural networks. Here, we need to train two neural networks. One is a decision network. We download millions of amateur Go games from the Internet. Through supervised learning, we let Alpha. The dog simulates the behavior of human beings in go; we randomly select a falling point from the board, train the system to predict the next step humans will make; the system's input is in the top five or top ten position where that particular position is most likely to occur. Move; this way, you only need to look at the 5-10 possibilities without analyzing all 200 possibilities.
Once we have this, we train the system for millions of times, reinforce learning with errors, and for the winning situation, let the system realize that the next time a similar situation occurs, it is more likely to make a similar decision. If, on the other hand, the system loses, then the next time something similar happens, it will not be chosen. We built our own game database and trained the system through millions of games to get a second neural network. Select different points of falling, learn through the confidence interval, and choose a situation that can win. The odds are between 0-1, 0 is impossible to win, and 1 is 100%.
By combining these two neural networks (decision networks and numerical networks), we can roughly estimate the current situation. The two neural network trees, through the Monte Carlo algorithm, can solve this problem that could not be solved. We took most of the game under Go and then played against the European Go Championship. The result was that the Alpha Dog won. This was our first breakthrough, and the algorithm was also published in the journal Nature.
Next, we established a one-million-dollar bonus in South Korea, and in March 2016, we competed against world Go champion Li Shishi. Mr. Li Shishi is a legend of the chess world and has been considered the top Go expert for the past 10 years. We played against him and found that he had a lot of innovative gameplay, sometimes Alpha dogs are difficult to control. Before the game started, everyone in the world (including himself) believed that he would easily win the five games, but the actual result was that our Alpha dog won 4:1. Go experts and experts in the field of artificial intelligence all call this epoch-making significance. For industry professionals, it had never been thought before.
4. Which key area of ​​chess is ignored by humans?
This is a once-in-a-lifetime accident for us. In this game, 2.8 billion people around the world are paying attention and more than 35,000 reports about this. The whole South Korea week is around this topic. It is a very wonderful thing. For us, it is not the Alpha Dog that wins this game. It is important to understand how he wins and how strong the system is. Alpha dog is not just imitating other human players. He is constantly innovating. Here is an example. This is a situation in the second game. Step 37, which is my favorite step in the whole game. Here, black represents the alpha dog, and he places the pawn on the triangle in the figure. Why is this step so crucial? Why everyone is shocked.
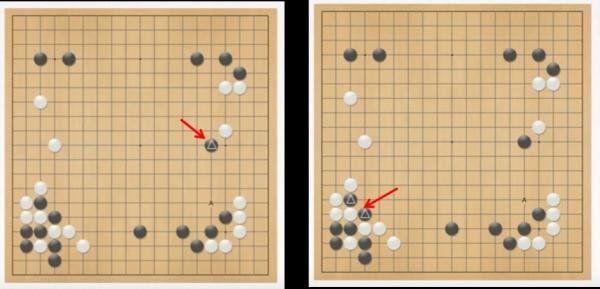
Left: In the second inning, step 37, the position of the black game is located on the remote side of the road. X é¥ è‘肜Ь è‘肜Ь XII/p>
In fact, there are two crucial dividing lines in Go, the third line from the right. If you move a piece on the third line, it means that you will occupy the area to the right of this line. And if you fall on the fourth line, it means that you want to go to the middle of the board. Potentially, in the future you will occupy the other areas of the board, which may be equal to the field you got on the third line.
So in the past 3,000 years or so, people thought that falling on the third line had the same importance as falling on the fourth line. But in this game, everyone saw that in Step 37, the Alpha Dog fell on the fifth line and entered the central area of ​​the game. This line is closer to the central area than the fourth line. This may mean that for thousands of years people have underestimated the importance of the central region of the game.
Interestingly, Go is an art and an objective art. Everyone we sit here may generate hundreds of new ideas because of good or bad mood, but it does not mean that every idea is good. The Alpha dog is objective. His goal is to win the game.
5. Which Alpha Dog wins Li Shishi’s trick?
As you can see, under the current chess game, the two triangles in the lower left corner seem to be in difficulty. After 15 steps, the power of these two pieces spreads to the center of the chess board and continues to the right of the chess board. Making this 37th step fall right here is a decisive factor in winning. Alpha Dog is very innovative in this step. I am a very amateur player. Let us look at a world-class expert Michael Redmond's evaluation of this step. Michael is a 9-segment player (the highest section of Go). Like the black section in Kung Fu, he said: “This is a very shocking step, like a wrong decision.†In the actual simulation, In fact, Michael initially placed the piece in another place. He did not expect the Alpha dog to take this step. Like this innovation, there are many Alpha dogs in this game. Here, I am particularly grateful to Mr. Li Shishi. Actually, when we won the first three games, he went down.
March 2016 Alpha Dog World World Go Champion Li Shishi defeated humans with a total score of 4:1.
It was three very difficult games, especially the first one. Because we need to constantly train our algorithm, Alpha Dog won the European Championship before. After this game, we knew the difference between the European Championship and the World Championship. In theory, our system has also improved. But when you train this system, we do not know how much is overfitting, so before the end of the first game, the system does not know its own statistics. So, in fact, we were very nervous in the first game, because if the first game is lost, it is very likely that there are huge loopholes in our algorithm, and we may lose five games in a row. But if we win the first game, prove that our weighting system is correct.
However, when Mr. Li Shishi came back in the fourth game, perhaps the pressure eased a lot. He made a very innovative move. I think this is a historical innovation. This step confuses the Alpha Dog and makes his decision tree miscalculated. Some Chinese experts even call it "the golden move." Through this example, we can see how much philosophy is implicated in Go. These top experts use their energy to find out this kind of gold move. Actually, in this step, the Alpha Dog knew that this was a very unusual step. He estimated that the probability of Li Shishi’s winning through this step was 0.007%. Alpha Dog had never seen such a way before, in those 2 minutes, He needs to search for decision calculations again. I have just mentioned the impact of this game: 2.8 billion people watched, 35,000 articles related to the media reported that Go was sold out in the Western market. I heard that MIT (Massachusetts Institute of Technology) has many other In colleges and universities, many people newly joined the Go game club.

In the fourth inning, Li Shishi's step 78 innovation.
I just talked about intuition and innovation. Intuition is an implicit expression. It is a form of thinking based on human experience and instinct and does not require precise calculations. The accuracy of this decision can be judged by the behavior. In Go, it is very simple. We input the position of the piece to the system to assess its importance. The alpha dog is simulating human intuition. Innovation, I think it is based on the existing knowledge and experience, to produce a primitive, innovative point of view. The Alpha dog clearly demonstrates both capabilities.
6. Is the mysterious chess player Master Alpha Dog?
Then our theme today is “to exceed the limits of human cognitionâ€. What should be the next step? Since March of last year, we have been continuously improving and improving the Alpha Dog. Everyone will certainly ask, since we are already a world champion, what else can be improved? In fact, we think Alpha Dog is not perfect, but we need to do more research.
First, we want to continue to study the game mentioned in the fourth game with Li Shishi just to fill in the knowledge gap; this problem has actually been solved. We have established a new alpha dog system, different from the main system. This branch system is used to confuse the main system. We also optimized the behavior of the system. It used to take us at least 3 months to train the system. Now it only takes a week.
Second, we need to understand the Alpha Dog's decision and explain it; what is the reason for the Alpha Dog to do so, whether it meets human thoughts, etc.; we do this by comparing the response of the human brain to different positions of the dog and Alpha Dogs. Responsive to the position of the pieces in order to find some new knowledge; essentially want to make the system more professional. We competed against the top experts in the world on the Internet. We used a pseudonym (Master) at the beginning and were guessed as Alpha dogs after the winning streak. These are the top experts, and we have won 60 masters so far. If you do a simple Bayesian analysis, you will find that Alpha Dog is not the same difficulty to win different opponents. Moreover, the alpha dog is constantly self-innovating. For example, the pawn (circle) at the lower right corner of the figure falls on the second line. In the past, we did not think this is a valid position. In fact, some South Korean teams have made an appointment for these games and want to study new meanings and information.
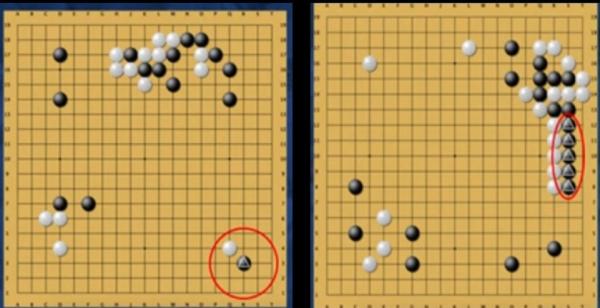
Alpha dog self-innovation, falling in the second grid of the flag.
Ke Jie is both a Chinese Go champion and the current World Go champion. He is only 19 years old. He also played online with Alpha Dogs. After the game, he said that mankind has studied Go for thousands of years. However, artificial intelligence tells us that we haven't even opened the skin. He also said that the combination of human and artificial intelligence will create a new era and will jointly discover the true meaning of the game. In a similar way, Ke Jie mentioned the truth of Go. We are here talking about the truth of science.

Mysterious chess player popular in the network won the Ke Jie on Tencent Go chess platform on January 3, 2017.
The Master holds the whiteboard and wins Ke Jie. Master is an upgraded version of AlphaGo.
So is the new era of Go really coming? This epoch-making event in the history of Go has happened twice. The first time occurred in Japan around 1600. In Japan during the 1930s and 40s, Wu Qingyuan, a very outstanding Go player from Japan, proposed a brand new game about Go. The theory has raised Go to a whole new realm. Everyone said that Alpha Dog now brings about the third revolution in the chess world.
7. Why does artificial intelligence "Go Go" stronger than "Go Chess"?
I would like to explain why the contribution of artificial intelligence in the chess world is far greater than that of chess. If we look at the current world chess champion Mannus Carlsson, he is not really different from the previous world champions. They are all excellent and smart. But why can they surpass humanity when artificial intelligence emerges? I think the reason for this is that chess is more tactical and Alpha Dog is more strategic. Nowadays, the world's top chess programs do not make technical mistakes. In humans, it is impossible not to make mistakes.
Second, chess has a huge database. If there are less than nine chess pieces on the board, it can be calculated by mathematical algorithm who wins. Computers can be calculated by thousands of iterative algorithms. Therefore, when there are fewer than nine pieces on the board, there is no way for the man to win the next game.
Therefore, the algorithm of chess has almost reached the limit, and we have no way to improve it. However, Alpha Dogs in Go are constantly creating new ideas. When these new ideas are confronted with real people, the top players can also incorporate them into the scope of consideration and continuously improve themselves.
Just like the European Go champion Fan Yan (the first human professional player to play against the Alpha dog), in the process of confrontation with the Alpha dog, the robot continues to innovate under the law, so that humans continue to jump out of their own thinking. Limit yourself to continuous improvement. Everyone knows that after more than 30 years of training in professional Go schools, many of their thoughts have been solidified, and robots' innovative ideas can bring unexpected inspiration to them. I really believe that if humans and robots are combined, they can create many incredible things. Our nature and true potential will be truly released.
8. What is Alpha Dog not to win the game?
Just as astronomers use the Hubble Space Telescope to observe the universe, using Alpha Dogs, Go experts can explore their unknown world and explore the mysteries of the Go world. We invented the Alpha Dog, not to win the Go game. We wanted to build an effective platform for testing our own artificial intelligence algorithms. Our ultimate goal is to apply these algorithms to the real world and serve the society.
One of the great challenges facing the world today is excessive information and complex systems. How can we find the laws and structures in them? From diseases to climate, we need to solve problems in different fields. These fields are very complicated. Even the most intelligent humans cannot solve these problems.
I think artificial intelligence is a potential way to solve these problems. In this era of new technologies, artificial intelligence must be developed and used within the scope of human morality. Originally, technology was neutral, but the purpose of our use of it and the scope of its use have greatly determined its function and nature. This must be a technique that will benefit everyone.
My own ideal is through my own efforts to make artificial intelligence scientists or artificial intelligence assistants and medical assistants possible. Through this technology, we can really speed up technology updates and advancements.
(The author of this article is a doctoral student of neurology at Cambridge University in the United Kingdom. His father, AlphaGo's father, Hasabis, is an alumnus of Cambridge University. The article's subtitle is edited by the editor.)
Father of AlphaGo Hasabis's "Exceeding the Limits of Human Cognition" Full Version
#endText .video-info a{text-decoration:none;color: #000;} #endText .video-info a:hover{color:#d34747;} #endText .video-list li{overflow:hidden;float: Left; list-style:none; width: 132px;height: 118px; position: relative;margin:8px 3px 0px 0px;} #entText .video-list a,#endText .video-list a:visited{text-decoration: None;color:#fff;} #endText .video-list .overlay{text-align: left; padding: 0px 6px; background-color: #313131; font-size: 12px; width: 120px; position: absolute; bottom : 0px; left: 0px; height: 26px; line-height: 26px; overflow: hidden;color: #fff; } #endText .video-list .on{border-bottom: 8px solid #c4282b;} #endText .video -list .play{width: 20px; height: 20px; background:url(http://img1.cache.netease.com/video/img14/zhuzhan/play.png);position: absolute;right: 12px; top: 62px;opacity: 0.7; color:#fff;filter:alpha(opacity=70); _background: none; _filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src="http://img1.cache.netease.com/video /img14/zhuzhan/play.png"); } #endT Ext .video-list a:hover .play{opacity: 1;filter:alpha(opacity=100);_filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src="http://img1.cache.netease.com/video /img14/zhuzhan/play.png");}
Displacement sensor, also known as linear sensor, is a linear device belonging to metal induction. The function of the sensor is to convert various measured physical quantities into electricity. In the production process, the measurement of displacement is generally divided into measuring the physical size and mechanical displacement. According to the different forms of the measured variable, the displacement sensor can be divided into two types: analog and digital. The analog type can be divided into two types: physical property type and structural type. Commonly used displacement sensors are mostly analog structures, including potentiometer-type displacement sensors, inductive displacement sensors, self-aligning machines, capacitive displacement sensors, eddy current displacement sensors, Hall-type displacement sensors, etc. An important advantage of the digital displacement sensor is that it is convenient to send the signal directly into the computer system. This kind of sensor is developing rapidly, and its application is increasingly widespread.
Magnetic Scale Linear Encoder,Magnetic Scale Encoder,Encoder Software,Encoder Meaning
Changchun Guangxing Sensing Technology Co.LTD , https://www.gx-encoder.com