
The relationship between machine learning and data mining
In the eyes of most non-computer professionals and some computer professional backgrounds, Data Mining and Machine Learning are two deep areas. In my opinion, this is a habitual misunderstanding that is too high to "seek" (I have added a lot of attributives here). In fact, these two fields, like other areas of computers, are constantly proficient and in-depth in the process of integrating theory and practice. The only difference is that they infiltrate more mathematical knowledge (mainly statistics). In the article I will try to explain these mathematical knowledge to you in a way that is easier to understand. This article analyzes their relationships and similarities and differences from the basic concepts, not to mention specific algorithms and mathematical formulas. I hope to help everyone.
Several related examplesFirst, let's give you some examples of life-related applications related to data mining and machine learning to help you better understand.
Example 1 (association problem):
Students who go to the supermarket often may find that some of the items we listed on the shopping list in advance may be placed in the adjacent area by the supermarket aunt. For example, there will be butter next to the bread counter, and there will be old gods near the noodle counter. This kind of item placement will make our shopping process faster and easier.
So how do you know which items should be placed together? Or how likely is it that a user buys another item while purchasing one item? This is to be solved by using related algorithms for relational data mining.
Example 2 (classification problem):
In the noisy square, people around you come and go. Looking closely at their appearance, clothing, words and deeds, etc., we will unconsciously conclude that this person is a Xinjiang native, a Northeastern or a Shanghai native. For example, in the just-concluded 2015 NBA Finals, various authorities will analyze the historical data of the Cavaliers and the Warriors in large numbers to determine whether the Cavaliers or the Warriors will win.
In the first example above, due to the large number of regions, this is a typical multi-classification problem when geographically classifying people. In the second example, various agencies predict whether the Warriors will beat the Cavaliers to win. This is a two-category problem, and the results are only two. The second classification problem is unusually high in the industry, such as predicting whether a person will buy a certain item in the recommendation system, other such as earthquake prediction, fire prediction, and so on.
Example 3 (cluster problem):
"Things are gathered together, people are divided into groups, and there are shadows of clustering problems everywhere in life." Assuming that the bank has a history of consumption records of several customers, now that it needs to add several wealth management products to different groups of people due to business expansion, how can we accurately recommend different wealth management products to different people by telephone message? This is a clustering problem. Banks generally cluster all users, users with similar characteristics belong to the same category, and finally recommend different wealth management products to customers of the corresponding category.
Example 4 (regression problem):
A regression problem, or a prediction problem, is also an application that is quite grounded in life. As we all know, securities companies will use historical data to predict the stock price movements for a period of time or one day. Similarly, real estate developers will also make pricing forecasts for properties on different floors depending on the geographical situation.
Both of the above examples are typical representatives of regression problems, which often predict a real value for a target under a given condition based on certain historical data.
I believe that after the above-mentioned easy-to-understand examples, you should have a preliminary understanding of what data mining and machine learning will be applied to. (The four types of problems listed here are very common, and of course applications such as anomaly detection, etc.) Faced with Why in the three elements of a new problem. The following explains what machine learning and data mining (ie What) and their relationships and similarities and differences.
Data miningData mining is also translated into data mining and data mining. It is a step in Knowledge-Discovery in Databases (KDD). Data mining generally refers to the process of searching for information hidden in it from a large amount of data through an algorithm. Data mining is often associated with computer science and achieves these goals through statistics, online analytical processing, intelligence retrieval, machine learning, expert systems (reliant on past rules of thumb), and pattern recognition.
From the above definition, it can be seen that data mining is a more biased application area than machine learning. In fact, data mining is a cross-disciplinary subject. When dealing with various problems, as long as we understand the business logic, we can turn the problem into a mining problem.
The process of data mining generally includes data preprocessing (ETL, data cleaning, data integration, etc.), data warehouse (which can be DBMS, large data warehouse and distributed storage system) and OLAP, using various algorithms (mainly machine learning Algorithm) for mining and final evaluation.
In short, data mining is a series of processes, and the ultimate goal is to mine the information you want or unexpectedly harvest from the data. The diagram below shows the many application areas of data mining.

In the previous section, we discussed the related concepts of data mining. In this section, we continue to discuss the basics of machine learning, learning methods, and common algorithms.
The subject of machine learning is the question of how computer programs automatically improve performance as experience accumulates. - Tom Mitchell
The above definition is the definition given by Tom Mitchell in his book Machine Learning. This definition is simple and straightforward but contains too much.
Popularly, we write a program that lets the computer carry out a learning process on its own until it reaches a level of satisfaction. So what is the purpose of learning? How to learn? How is the level of satisfaction defined?
Usually, assuming that our goal is a funcTIon f, we will provide the computer with some training data for learning training. Each learning will train a hypothesis h, when h and f are getting closer and closer as the computer continues to learn. When it is said, h is getting more and more satisfied. The measure of satisfaction is measured by the error e (different ways for different situations). More simply, machine learning is the process of finding a suitable objective function through data training. At present, the machine learning discipline has applied a large amount of statistical knowledge, which we also call statistical machine learning.
Let me explain to you a few concepts that you must know.
learning methodThere are different ways to model a problem, depending on the type of data. It is a good idea to classify the algorithm according to the learning method. This allows people to consider the most appropriate algorithm based on the input data to get the best results when modeling and algorithm selection. In the field of machine learning, there are several main ways to learn:
1. supervised learning
Under supervised learning, each group of training data has a clear identification or result. For example, “Xinjiangâ€, “Shanghai†and “East†in the geographical classification of people belong to the geographical indication. When establishing a predictive model, supervised learning establishes a learning process, compares the predicted results with the actual results of the “training dataâ€, and continuously adjusts the predictive model until the predicted results of the model reach an expected accuracy.
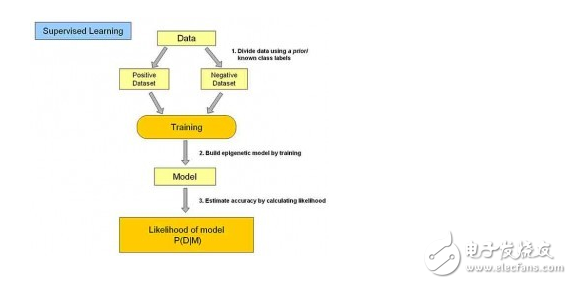
The classification and regression problems in the above examples are all in the scope of supervised learning. Commonly used classification algorithms include: Decision Tree (refer to my previous article), NaTIve Bayesian Classifier, Support Vector Machine (SVM) based classifier, neural network method ( Neural Network), k-nearest neighbor (kNN), etc.
2. Unsupervised learning
In unsupervised learning, data is not identified, and the learning model is used to infer some of the inherent structure of the data. The association and clustering problems in the previous four examples belong to the category of unsupervised learning. Common algorithms in association problems include Apriori (the algorithm is based on Spark's parallelization algorithm refer to my previous article), FP-Growth and Eclat, etc., and the most classic algorithm in clustering problem is k-Means.
3. Semi-supervised learning
In the semi-supervised learning learning mode, the input data part is identified and the part is not identified. This learning model can be used for prediction, but the model first needs to learn the internal structure of the data in order to reasonably organize the data for prediction. The application scenario includes classification and regression. The algorithm includes some extensions to the commonly used supervised learning algorithms. These algorithms first attempt to model the unidentified data, and then predict the identified data. Graph Inference or Laplacian SVM.
4. Reinforcement learning
In this learning mode, the input data is used as feedback to the model. Unlike the supervised model, the input data is only used as a way to check the model right or wrong. Under the reinforcement learning, the input data is directly fed back to the model, and the model must Make adjustments immediately. Common application scenarios include dynamic systems and robot control. Common algorithms include Q-Learning and Temporal difference learning.

In the above we introduced the basic concepts of machine learning and data mining, applications, related algorithms and so on. Next, we will continue to discuss the relationship and similarities between the two.
Statistics - 1749
Artificial Intelligence - 1940
Machine learning - 1946
Data Mining - 1980
From the development of history, data mining is a new subject. It is built on a powerful knowledge system and uses a large number of machine learning algorithms. At the same time, according to the previous section, data mining also uses a series of Engineering technology. Machine learning is a discipline that is supported by statistics. It does not need to consider application engineering techniques such as data warehousing and OLAP.
to sum upMachine learning is a more theoretical subject, the purpose of which is to let the computer continuously learn to find the hypothesis h close to the objective function f. Data mining is an applied discipline that uses a wide range of knowledge, including machine learning algorithms. It uses a series of processing methods to mine the information behind the data.
ceramic cap
ceramic cap
YANGZHOU POSITIONING TECH CO., LTD. , https://www.cnpositioning.com